Designing an Agent Reading Test
In which I try to give people tools to understand how agents read web content, and where they fail.
In which I try to give people tools to understand how agents read web content, and where they fail.
In which I revisit measuring agent web traffic, and dive deeper down the rabbit hole.
In which I share research about why LLM-generated output is hard to fact check.
In which verification is the hardest unsolved problem in AI content pipelines, and most organizations don't know it.
In which I find that a platform-published spec's omissions track financial incentives.
In which I use AI to help draft content, and discover its limitations.
In which I build a system to filter AI-related content.
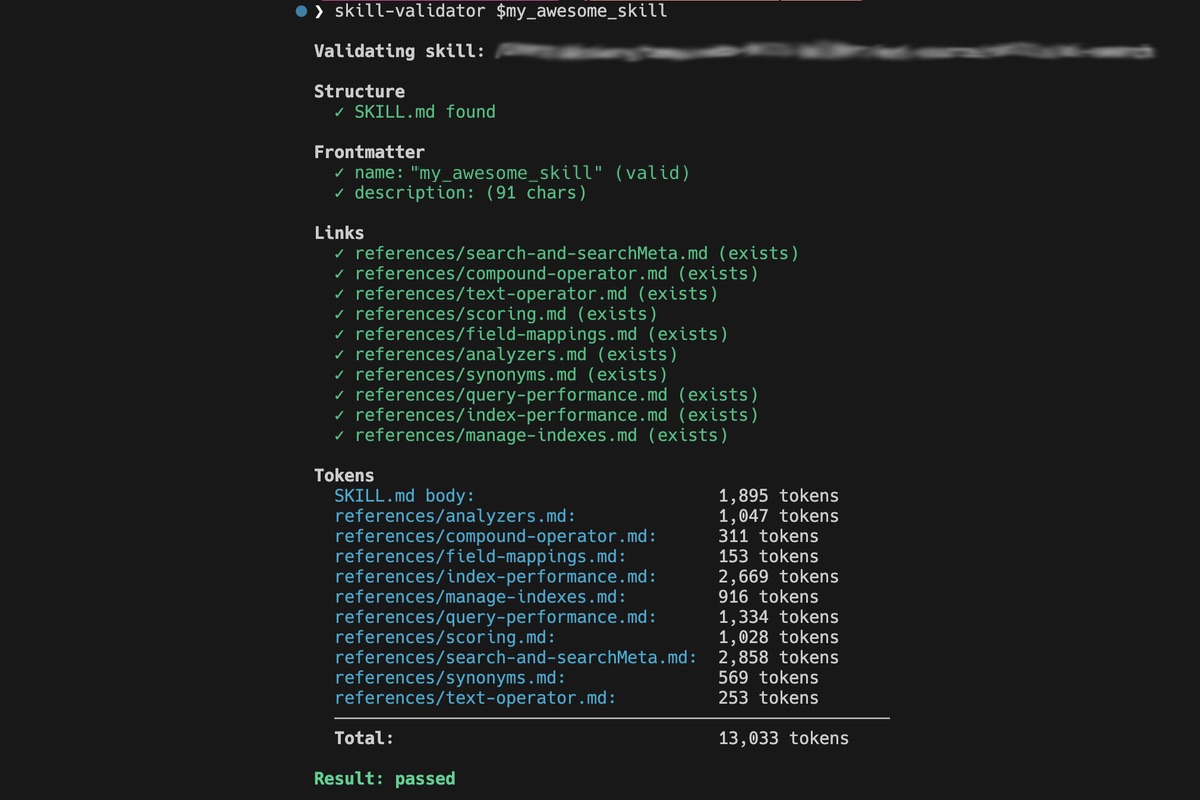
In which someone asks for something in 'skill-validator' and I spin up a new community research project.
In which a platform breaks the Agent Skills spec for its own benefit.
In which I build a freshness check for llms.txt and discover that my tools were the problem.
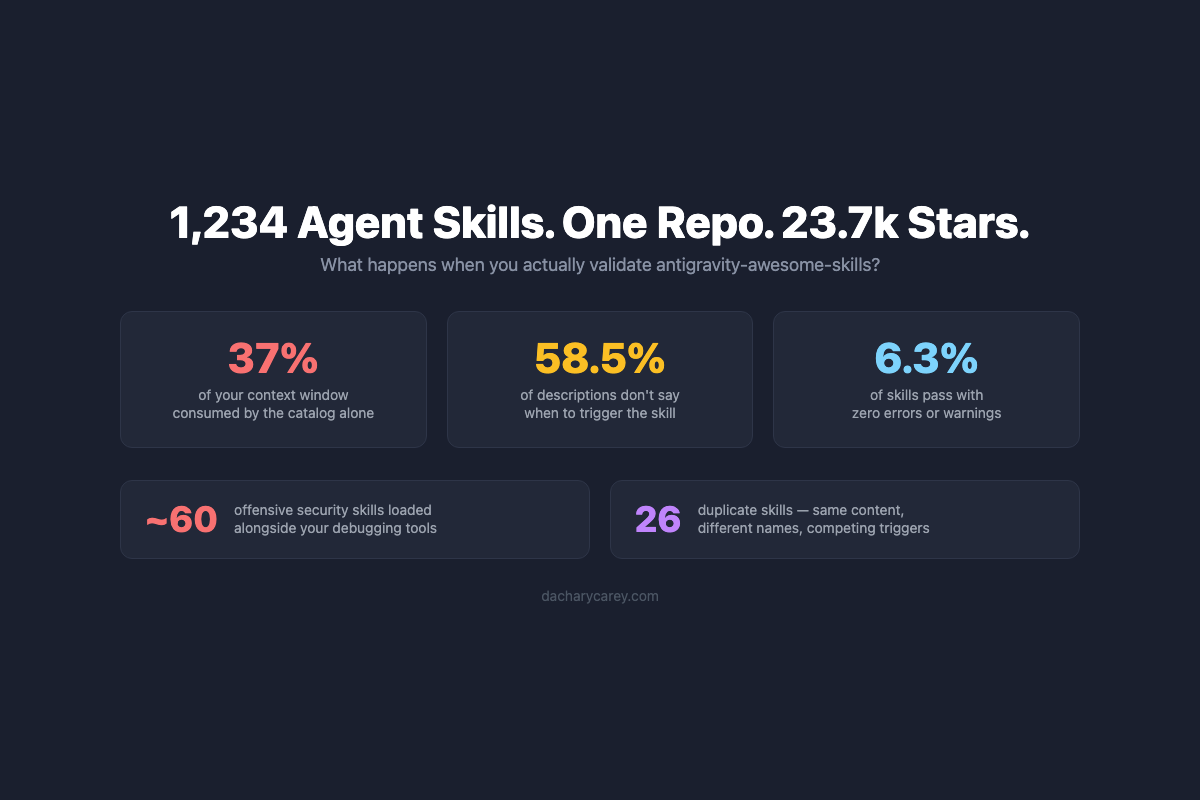
In which I validate a 23.7k-star skill mega repo and discover problems the star count won't tell you.
In which I explain why a vibes-based approach to AI and docs ain't cutting it.
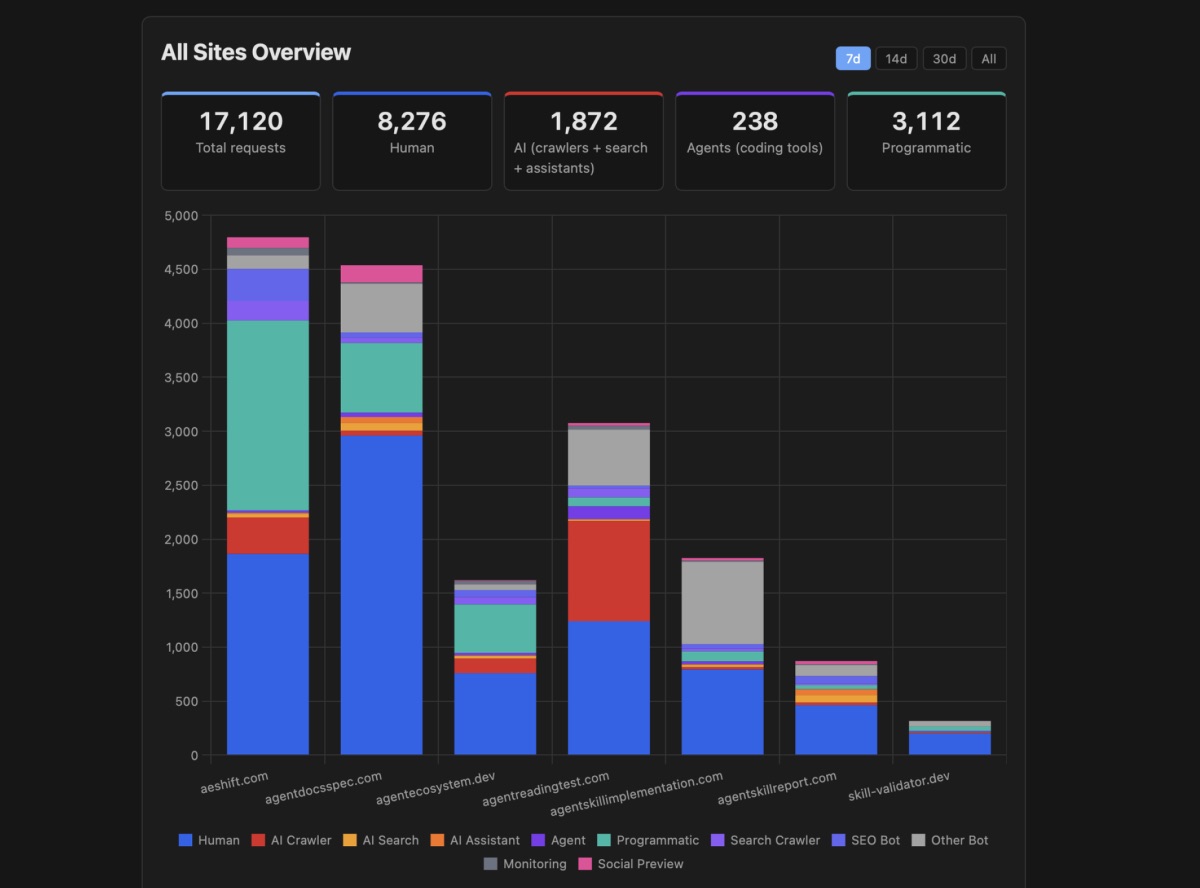
In which I lurk in server logs and try to make sense of what I see.
In which I talk about what's inside a coding agent.
In which I show you how I made multiple Hugo sites agent-friendly.
In which I deep dive on a Stripe Skill, and what it means for the industry.
In which I discuss how model training and agents need different docs access patterns.
In which I answer someone who asked me how to get started with AI.
In which I ask an agent to help me explore Web Fetch with docs pages - and get a surprise.
In which I ask an agent to view hundreds of docs pages - and feel sad.
In which I build a validator and analyze popular Agent Skills.